7.改版履歴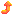
Ver1.16 1997/10/17
- import に EDICT (LSD-3) 形式の辞書を追加した.
- import に PDIC-EJ (LSD-3), PDIC-JE (LSD-3) 形式の辞書を追加した.
- import に エラーとなった行を表示する -error オプションを追加した.
Ver1.15 1997/10/15
- 辞書コンバータ import のバグ (henkei関数) のバグを修正した.
- import の変換機能を少しだけ強力にした.
Ver1.14 1997/10/12
- 辞書コンバータ import を作成した. ejdic, gene, trtext, etoj 形式の辞書をインポートできるが完全ではない.
- 重複した単語の訳語をマージする joindic コマンドを作成した.
Ver1.13 1997/10/09
- CGIから webget への URL の渡し方を、環境変数に変更した.これでコマンドラインから渡すよりも少しは安全になった. webget 自体は今まで通りコマンドラインから URL を取得することも可能です.
- webdict.dic の語数を 3000 語ほど追加した (現在約 78700語).
- misc/exist.c を作成した.これで未登録単語のみ抽出できる.
- webdict.html-dist 中の余計なコードを削除した.
Ver1.12 1997/10/08
- 語尾変化テーブルを定義ファイル (dic/tail.dic) に移した.
- 語尾変化 "ing" -> "y" を追加した.
- cgi.cの不要な機能を削除し最小限の機能だけ含めるようにした.
- 語尾変化が "" のときテーブルに追加しないようにした.
- 辞書の形式を調べる checkdic を作成した.
- checkdic により、辞書の形式をチェックし修正した.
- checkdic で調べる項目を増やした.
- SIGPIPE をトラップするようにした.
Ver1.11 1997/10/03
- META HTTP-EQUIV="Content-Type" が無い場合に埋め込むようにした.これは、MSIE4.0が文字化けするための対処です.
- cgi.c で取る最低限のログ (log_mode=2) を 1行で収まるようにした.
Ver1.10 1997/10/02
- インデックスファイルの作成および読み込み時にファイルをロックするようにした.
- インデックス読み込み時に辞書より古いとき、インデックスの再作成をするようにした.
- URLの文字として "#" を許可した.
- リンク書き換え時の相対パス URL で、ファイルパスとファイル名の間の "/" が抜けていたのを修正した.
- webget で、URL にセクション "#" が指定されている場合は、それ以降を削除してからURLの取得を行うように修正した.
- BASE HREF タグの挿入で、ホスト名だけでなくパス指定も含めるようにした.
- umask(002) を指定するようにした.
- 環境変数 (LANG=japan, TZ=JST-9) を設定するようにした.
- 熟語の最大語数を指定 (max_idiom) できるようにした.
- showdic に verbose モード (/v) を追加した.
- makefile と conf.c, cgi.c の定義ファイルのdefine名称が違っていたものを修正した.
Ver1.09 1997/09/26
- 辞書をインデックスファイル型に変更した.
- dict.c を分割し tail.c を作成した.
- 熟語および語尾変化での訳語が REPORT_SHORT 形式でないバグを修正した.
- Copyright を追加した.
- flex_word_tail の引数誤りを修正した(小文字で検索していた).
- 語尾変化に pping, tting を追加し、順序を最適化した.
- 辞書の初期化の場所を変更した.
- URL の文字として ":" を許可した.
- 英語と訳語が同一の時の処理を正常に動作するよう変更した.
- 辞書インデックス作成の表示を詳細にした.
- showdic の対話形式を親切にした.
- 語尾変化に er->e を追加した.
- 語尾変化テーブル(長さの計算)の初期化 (tail_init) を追加した.
- duration の計算を細かく (time->gettimeofday) した.
- タグ関係のサブルーチンを mainloop.c から分割し meta.c とした.
- news://, nntp:// タグを追加した.
- 単語の文字に ";","&", "#"を追加した (&, <, >, &#xxx; に対応するため).
- encode_url, cut_url のバグを修正した.
- 辞書に品詞を記述できるように dic_fgets 関数を作成した.
- encode_url での不正な free 関数の呼び出しを削除した.
- © に対応するため "#" を追加し ";" の語尾を追加した.
- showdic 実行時は unknown.dic を作成しないようにした.
- showdic に translation 機能を追加した.
- ":", ";", "/" の語尾変化を追加した.
- dict_root を追加し、実行ディレクトリを指定するようにした.
- showtag.c において tag 共通関数は tag.c のものを使うようにした.
- *.h に重複読み込み防止の #ifndef, #define ~ #endif を記述した.
- tag のトークンの切れ目を調べるようにした.
- AREA HRE Fタグも書き換えるようにした.
- encode_string のバグ (char * -> unsigned char *) を修正した.
- gettimeofday 関数の引数の誤りを修正した.
- cgi.c の cftime 関数を strftime 関数に置き換えた.
Ver1.08 1997/09/18
- A HREF タグを書き換えて CGI でも翻訳フィルタを介せるようにした.
- CGI で GET メソッドを受け入れるようにした.
- これ以降では、各ソースのバージョンをメジャーバージョンに統一するようにした(今までは、ソースのバージョンは個別で無関係だった).
- 語尾のピリオドを単語に含むようにした。単語のマッチは語尾変化で対応する.
- Sept. Mr. 等の略語に対応するため.
- version.h をすべてのモジュールがインクルードするようにした.
- createdic で stdin からの原文辞書入力を可能にした.
- capacity を追加した(テキストデータでないと判断する境界値).
- ソース中のすべての jukugo を idiom に変換した.
- 6単語の熟語まで認識するようにした.
- base_target を追加した.
- 括弧付きの単語をフォントを小さくして表示する font_size を追加した.
- createdic で統計情報を詳細に出すようにした.
- dict_level の値は 4 をデフォルトにした.
- dict_dir を word_dir に変更した(初期値も dic から word へ).
- 単語に ":", ";", "&" を追加した.
Ver1.07 1997/09/10
- webdict.cgi を新規に追加した.
- 出力時に HTTP ステータスヘッダを落とすオプション (-status yes/no) を追加した.
- webget を新規に作成した。指定のURLを取得するプログラム.
- ピリオドなどの特殊記号が続くときは単語の切れ目と判断するようにする.
- モジュールを分割した.
- FORM_REVERSE を FORM_DUAL (オプション名に統一) に改名した.
- 熟語辞書と単語辞書を分けた.
- 5単語熟語まで認識できるようにした.
- 高速化のため2,3単語熟語が存在するか検査する処理を追加した.
- 処理に要した時間を表示 (verbose モードで) するようにした.
- "訳語[英語]" の表示形式 (FORM_DUAL) を追加した.
- "訳語<!--英語-->" の表示形式 (FORM_REMARK) を追加した.
Ver1.06~Ver1.01
Ver1.00
|